
One of the main issues facing libraries as they work to create richer user services is the complexity of their systems environment. Consider these pictures which I have been using in presentations for a while now.
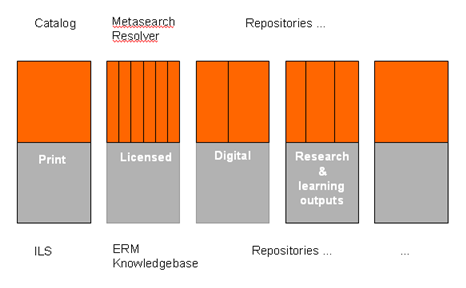
Reductively, we can think of three classes of systems – (1) the classic ILS focused on ‘bought’ materials, (2) the emerging systems framework around licensed collections, and (3) potentially several repository systems for ‘digital’ resources. Of course, there are other pieces but I will focus on these.
In each case what we see is a backend apparatus for managing collections, each with its own workflow, systems and organizational support. And each with its own – different – front-end presentation and discovery mechanisms. What this means is that the front-end presentation mirrors the organizational development over time of the library backend systems, rather than the expectations or behaviors of the users.
You have the catalog here, maybe several options for licensed resources (a-to-z, metasearch, web pages of databases, and so on) over there, and potentially several repository interfaces (local digitized materials, institutional repository) somewhere else.
This is one reason that people have difficulties with the library website. Effectively, it is a layer stretched over a set of systems and services which were not designed as a unit. Indeed, in some cases, they were not originally designed to work on the web at all. So what do we have?
ILS: a management system for inventory control of the ‘bought’ collection (books, DVDs, etc). The catalog is bolted onto this and gives a view onto this part of the collection. In effect, in virtue of its integration with inventory management, the catalog provides discovery (what is in the collection), location (where those things are) and request (get me those things) in a tightly integrated way. The ILS and catalog may be part of a wider apparatus of provision, and may have mechanisms for interfacing to resource sharing systems of one sort or another. The management side may have interfaces to a variety of other systems for sharing and communicating data: procurement, finance, student records. And there will be a flow of data into the system, from jobbers, as part of a shared cataloging environment, and so on.
Licensed: This has been an area of rapid recent development as the journal literature moved to electronic form. On the backend we now see a variety of approaches, and the frontend can be very confusing with lists of databases and journals presented in various ways, often in uncertain relation to the catalog (where do I look for something?). We are now seeing the emergence here of an agreed set of systems around knowledge-base, ERM, resolution and metasearch, and there is rapidly developing vendor support. This is the range of approaches for which Serials Solutions has proposed the ERAMS name. These systems require the management of new kinds of data, and mechanisms are being put in place, certainly not yet optimal, for the creation, propagation and sharing of this data. With journals data, discovery, location and request are not so tightly coupled as they were with the catalog. Discovery has happened in one set of tools (A&I databases), but then the appropriate title may have to be located in another tool (the catalog for example) and, if not available locally, requested through yet another system. The importance of the resolver, and the enabling OpenURL, has been to tie some of these things together and remove some of the human labor of making connections between these systems. And metasearch has been seen as a way of reducing human labor by providing a unified discovery experience over disparate databases. However, this whole apparatus is still not as as well-seamed as it needs to be, and users and managers still do more work than they should to make it all work.
Repository: Libraries are increasingly managing digital materials locally and supporting repository frameworks for those. This includes digitized special collections, research and learning materials in institutional repositories, web archives, and so on. There are a variety of repository solutions available, some open source. Typically, the contents of the repository backend may be available to repository front-ends on a per-repository basis. Here, discovery (what is there), location (where is it) and request and delivery are typically tightly integrated. Repositories may also have interfaces for harvesting or remote query. On the management side, metadata creation and material preparation may still be labor-intensive.
OK, so here are some general observations about this environment:
- There is still a major focus – in terms of attention, organizational structures, and resource allocation – on the systems and processes around the ILS and the bought collection. In academic libraries, we will surely see some of this move towards the systems and processes around the licensed collections given the rising relative importance of this part of the collection. The repository strand of activity, associated with emerging digital library activities, may, in some cases, be supported from grant or other special resources. It will need to become more routine.
- The fragmentation of this systems activity, the multiple vendor sources, the different workflows and data management processes, and the absence of agreed simple links between things mean that the overall cost of management is high.
- There has been much discussion of library interoperability, but it has tended to be about how to tie together these individual pieces, or about tying pieces to other environments (how do I get my repository harvested for example). There has been less focus on how you might abstract the full library experience for consumption by other applications – a campus portal for example.
There is also another cost: diminished impact and lost opportunity. The awkward disjointedness described above also means that it is difficult to mobilize the consolidated library resource into other environments, course management or social networking systems for example. It is difficult to flexibly put what is wanted where it is wanted.
This in turn means several things.
- We will see more hosted and shared solutions emerge, which offer to reduce local cost of ownership. And, of course, we are seeing vendors consider more integration between products. In particular it is interesting seeing the concentration on support for the licensed e-resources emerge strongly, as well as discussion about integrated discovery environments.
- Over time, we can expect to see some more reconfiguration in a network environment. Shared cataloging and externalizing the journal literature have been two significant reconfigurations in the past. The pace of current developments suggest that we may be ready for other ways of collaboratively sourcing shared operations. For example, does it make sense for there to be library by library solutions for preservation, social networking, disclosure to search and social networking engines, and so on.
The next picture tries to capture an important direction that has emerged in the last year or so.
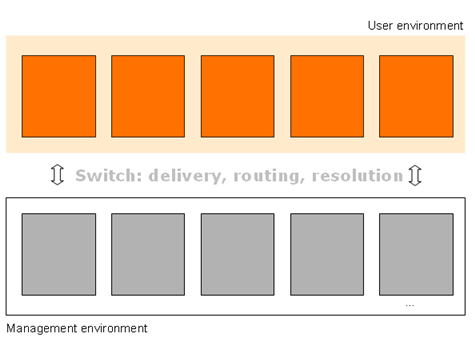
For many of the reasons identified above, we are seeing a growing interest in separating the discovery and presentation front end from the management backend across this range of systems. Why? Well, because it is becoming clearer as I suggested in my opening that legacy system boundaries do not effectively map user preferences. And because fragmentation adds to effort and accordingly diminishes impact.
What about the discovery side? So, we saw metasearch, a partial response to fragmentation of A&I databases. We are now seeing a new generation of products from the ‘ILS vendors’ which look at unifying access to the library collection: Encore, Primo, Enterprise Portal Solution. However, discovery has also moved to the network level. So, folks discover resources in Amazon, Google, Google Scholar. And OCLC is working to create discovery experiences which connect local and network through Worldcat Local, Worldcat.org and Open Worldcat.
And on the management side? Here the variety of workflows and systems adds cost, as resources are managed on a per-format basis. We can expect to see simplification and rationalization in coming years as libraries cannot sustain expensive diversity of management systems. The National Library of Australia’s discussion of a ‘single business’ systems environment, or Ex Libris’s discussion of Uniform Resource Management are relevant here. It is likely that there will be a growing investment in collaboratively sourced solutions, as libraries seek to share the costs of development and deployment.
As discovery peels off, then the issue of connecting discovery environments back to resources themselves becomes very important. It is interesting to look at Google Scholar in this regard, as different approaches are required for the three categories identified above. It has worked with OCLC and other union catalogs to connect users through to catalogs and the ILS; it has worked with resolver data to connect users through to licensed materials; and it has crawled repositories and links directly to digital content.
Given this great divide, several issues become very important:
- Routing, resolution and registries become critical, as one wants to enable users to move easily from a variety of discovery environments to resources they are authorized to use. We need a richer apparatus to support this. (I have discussed the role of registries elsewhere.)
- Libraries have thought about discovery. There is now a switch of emphasis to disclosure: libraries need to think about how their resources are best represented in discovery environments which they don’t manage. (I have also discussed disclosure in more detail elsewhere in these pages.)
- And again, how we present library services for consumption by other environments becomes an issue. For example, we are lacking an ILS Service Layer, an agreed way of presenting the functionality of the ILS so that it can be placed, say, in another discovery environment (shelf status, place a hold, etc).
- Better discovery puts more pressure on delivery, whether from a local collection, throughout a consortium, or in broader resource sharing or purchase options. Streamlining the logistics of delivery and providing transparency on status at any stage for the user (as they can do with UPS or Amazon) become more important.
And finally ….
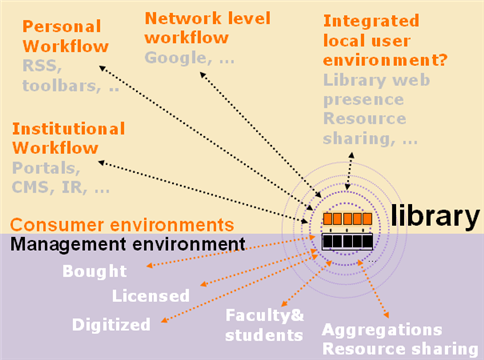
We are used to thinking about better integration of library services. But that is a means, not an end. The end is the enhancement of research, learning and personal development. I discussed above how we want resources to be represented in various discovery environments. Increasingly, we want to represent resources in a variety of other workflows. These might be the personal digital environments that we are creating around RSS aggregators, toolbars and so on. Or the prefabricated institutional environments such as the course management system or the campus portal. Or emerging service composition environments like Facebook or iGoogle. As well as in network level discovery environments like Google or Amazon that are so much a part of people’s behaviors.
Libraries need to focus more attention on reconfiguring library services for network environments. This is the main reason for streamlining the backend management systems environment. It does not make sense to spend so much time on non-value creating effort.
Related entries:
- Registries: the intelligence in the network
- Discovery and disclosure
- Lifting out the catalog discovery experience
- Discover, locate … vertical and horizontal integration
- Libraries, logistics and the long tail
- Library websites again
- Metasearch: a boundary case?
- In the flow
- The integrated library system that isn’t


