
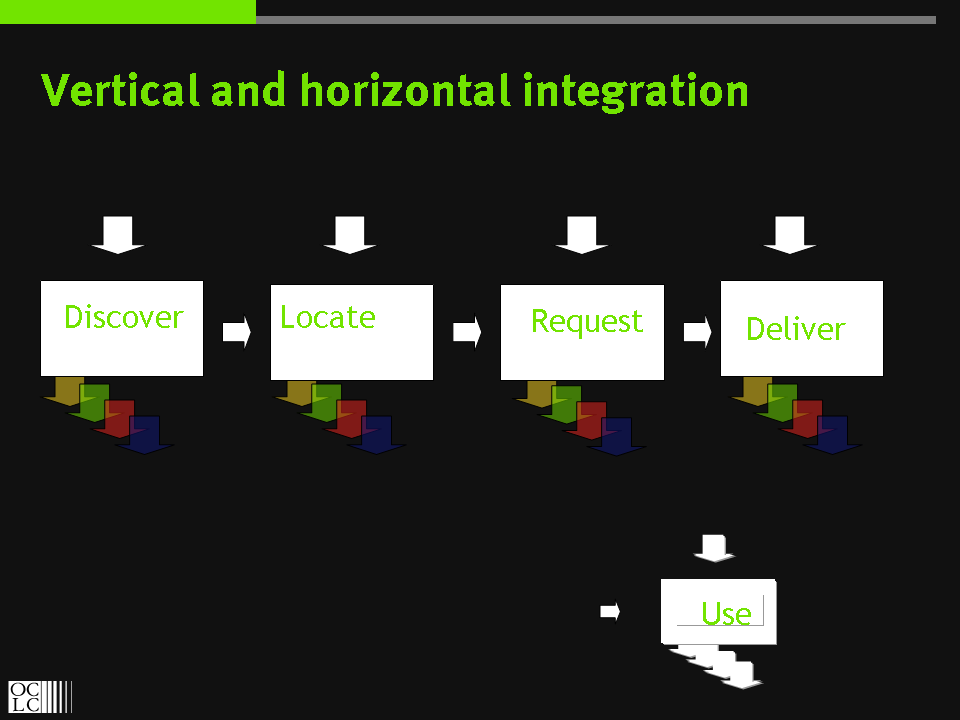
I was involved in some work years ago which developed the discover-locate-request-deliver string of verbs to talk about integrating library services. One emphasis of the work was that discovery was one part only of a whole chain (discovery2delivery – D2D) through which requirements were met. Requiring the user to complete the D2D chain by manual interactions dampened library use: writing down the results from an A&I search and then looking in the catalog to see if the journals were held, for example. As we look at resource sharing environments, we still see that we have imperfectly integrated the D2D verbs. In fact, the integration has been greater with journals as a major focus of the OpenURL resolver is to join up the D2D chain. One wonders whether it will make sense to put the catalog behind the resolver also, and it is certainly interesting to see the importance of resolution in some of the examples below. I now think of the verbs in this way:
- Discover. Discover that a resource exists. Typically, one may have to iterate to complete the discovery experience: search or browse candidate A&I databases, for example, and then search selected ones. The publish/subscribe model is increasingly important to discovery, as users subscribe to syndicated feeds. One of the major issues facing library users is knowing where to search or subscribe to facilitate relevant discovery
- Locate. Discover services on found resources. A service may be as simple as notifying somebody of a shelf location. Resolvers are important here: an OpenURL resolver will return services decided to be available on the resource indicated in the OpenURL.
- Request. Request a service. A user may select and initiate a found service.
- Deliver. The service is executed. A book is delivered, a document downloaded, or whatever.
Of course, other services will be deployed along the way: authorization, authentication, tracking, billing, etc.
What the web does is give us an integrated discover-locate-request-deliver experience. Some sophisticated infrastructure supports this concatenation: crawling and indexing by search engines, DNS resolution, ….
In library services the joins are more visible, and many of the places where one wants integration are precisely at the seams between these pocesses. Think horizontal and vertical as in the picture. The joins are horizontal where one wants to move between the processes, to traverse process boundaries. Having discovered that an article exists, one wants to find services that will make it available, and select one (or maybe have all of this done for you in the background, just as it does with a web page). The horizonal joins are most likely to be achieved within monolithic systems: the library catalog for example, which may allow you to discover, locate, request and have delivered items. Living in Ohio, one is very aware of the value to faculty and others of OhioLink. OhioLink closely integrates the D2D process for books on a systemwide level within Ohio higher education, and creates great value for its participants and users in so doing.
The joins are vertical where one wants to integrate activities within processes: metasearch is a topical example, where one is trying to integrate discovery across many resources. One may want to locate an item or service in several places – Amazon, the local catalog, a group of catalogs within a consortium – and present back to the user options for purchase or borrowing with indications of cost and/or likely delivery times. A request may be initiated through Inter-Library Lending or through a purchase order, and so on.
Much of the complexity of constructing distributed library systems arises from traversing the boundaries between these processes (horizontal integration) or from having unified interaction with services within a particular process (vertical integration). An example of the former is the difficulty of interrogating local circulation systems for status information; an example of the latter is differences in metadata schema or vocabularies across database boundaries.
I was reminded of the discover-locate-request-deliver string as I have been looking at various publicly available union/group activities recently, and these words crop up from time to time:
- RedLightGreen offers a rich discovery experience, based on aggregate data from the RLG union catalog. It also has a marvelous name 😉 – one of the few library initiatives to have a name worthy of the Internet times we live in. I speculate that it has not had the traction that one might have expected because it does not integrate the locate-request-deliver verbs so well into the discover experience.
- The recently visible Talis Whisper demonstration site gives a nice indication of how one might tie these things together, although not all the joins appear to be working in the available site. Interestingly, it offers the user tabbed access to discover, locate and borrow processes.
- The European Library (TEL) has a facility to search across European national libraries. This somewhat confuses the discovery experience as results are not rolled up into a single set for you. There is little integration of the other services. One can configure it with an OpenURL resolver of choice, but otherwise it does not offer much integration.
- CURL (which appears to have drifted clear of its acronymic mooring to become the Consortium of Research Libraries in the British Isles) lists as part of its vision to allow researchers, “wherever in the world”, to “search, locate and request all resources, whatever their format, easily and quickly from the desktop”. Some of those verbs again. One vehicle for achieving this vision is COPAC, a union catalog of the national libraries in the UK and 24 research libraries in the UK and Ireland. COPAC offers discovery over its constituent catalogs. Again, it allows outward OpenURL linking through an experimental user interface, using the OpenURL Router to land in the appropriate institutional resolver. (The OpenURL Router is a UK service which provides a central registry of OpenURL Resolvers. It is similar to, and preceded, OCLC’s OpenURL Resolver Regisry.)
- OCLC’s OpenWorldcat does not currently have a destination site; rather, entries may be discovered in Yahoo or Google, or be directly linked to. Where we recognize a user’s IP address we offer services (deep link to OPAC, user-initiated ILL, resolver) which we know they are authorized to use.
This cursory overview shows that we have intermittently and imperfectly managed to integrate location, request and delivery into systems whose focus is still largely discovery. However, discovery without fulfilment is of limited interest to an audience which wants D2D services which are quick and convenient, and which hide the system boundaries which need to be traversed in the background. I am also surprised, especially given the linking of discover services to locate services through the resolver in the journals arena, that we have not seen more linking of general discover services (e.g. Amazon) to library locate services (e.g. catalog/circ).
To complete the D2D chain efficiently in open, loosely coupled environments (that is, not within closed communities with tightly integrated systems environments) will require quite a bit of infrastructure development. Much of this relies on better metadata about institutions (libraries, branches), collections (databases, library collections, …) and services (how to connect to catalogs, ILL systems, resolvers, e-commerce sites, …), as well as about policies (for example, who can borrow from us and under what conditions) and terms. It is for this reason that we are seeing greater interest in registries and directories which will provide the ability to discover, locate, request and have delivered resources more effectively.
The picture is taken from an early presentation [ppt]I did at OCLC at a seminar organized by Erik Jul.
Related entries and article:
- All that is solid melts into flows
- From metasearch to distributed information environments
- A somewhat long article describing some of the work that led to discover-locate-request-deliver is available. It was published before the introduction of the OpenURL and it is interesting to think about the impact of context sensitive linking on some of the scenarios discussed there.
Update: Picture from presentation moved from text to feature picture. Abstract added.


