
I came across the Ernest Hemingway phrase ‘gradually, then suddenly’ in an online discussion recently. Here is the context on the useful Goodreads quotable quote page.
It seemed a statement appropriate to our times, and especially apt to a recent phenomenon: the growing importance of large-scale knowledge bases which collect data about entities and make relationships between them. Wikipedia is already an ‘addressable knowledgebase‘, which creates huge value. DBpedia aims to add structure to this. Perhaps more importantly, Wikidata is an initiative to create a machine- and human-readable knowledge base of all the entities in Wikipedia and allow them to be augmented with further data and links.
This is one of several examples, which although different in purpose, scope and sustainability model, collect and organize data about ‘things’. These are important because they collect and organize data in ways that support answering questions, and are machine-processable. They make ‘facts’ or ‘things’ discoverable, referencable, relatable. They become reference points on the web, or support services that become reference points on the web.
- Freebase: “An entity graph of people, places and things”. Freebase is now owned by Google and is a contributor to their newly publicized Knowledge Graph (more below). Alongside this, it is worth noting the strong interest in Schema.org, a way of adding descriptive markup to web pages. It is sponsered by Google, Microsoft, Yahoo and Yandex. An important role is that it allows search engines to harvest structured data.
- DBpedia/Wikipedia/Wikidata. “The DBpedia knowledge base currently describes more than 3.64 million things, out of which 1.83 million are classified in a consistent Ontology, including 416,000 persons, 526,000 places, 106,000 music albums, 60,000 films, 17,500 video games, 169,000 organisations, 183,000 species and 5,400 diseases.” As mentioned above, Wikidata is an initiative of the Wikimedia Foundation which will create an editable knowledge base of entities in Wikipedia. This will allow structured data about those entities to be shared across Wikipedia and across different language versions of Wikipedia, and with others. It will show up in the ‘info boxes’ on Wikipedia.
- Factual: Aims to “1. Extract both unstructured and structured data from millions of sources. 2. Clean, standardize, and canonicalize the data. 3. Merge, de-dupe, and map entities across multiple sources.”
- Wolfram Alpha “..a computational knowledge engine: it generates output by doing computations from its own internal knowledge base, instead of searching the web and returning links.”
Think of two important recent developments: Siri and Google’s inclusion of Knowledge Graph data in its results. Siri created a splash when it appeared. Among the sources it uses to provide answers are Yelp and Wolfram Alpha. Here is a results page from Google. The panel on the right shows the Knowledge Graph data …
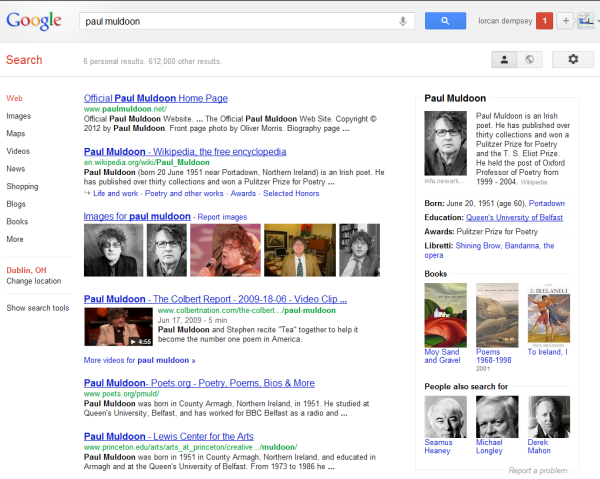
And here is how Google describes the rationale of the knowledge graph:
But we all know that [taj mahal] has a much richer meaning. You might think of one of the world’s most beautiful monuments, or a Grammy Award-winning musician, or possibly even a casino in Atlantic City, NJ. Or, depending on when you last ate, the nearest Indian restaurant. It’s why we’ve been working on an intelligent model–in geek-speak, a “graph”–that understands real-world entities and their relationships to one another: things, not strings. The Knowledge Graph enables you to search for things, people or places that Google knows about–landmarks, celebrities, cities, sports teams, buildings, geographical features, movies, celestial objects, works of art and more–and instantly get information that’s relevant to your query. This is a critical first step towards building the next generation of search, which taps into the collective intelligence of the web and understands the world a bit more like people do. Google’s Knowledge Graph isn’t just rooted in public sources such as Freebase, Wikipedia and the CIA World Factbook. It’s also augmented at a much larger scale–because we’re focused on comprehensive breadth and depth. It currently contains more than 500 million objects, as well as more than 3.5 billion facts about and relationships between these different objects. And it’s tuned based on what people search for, and what we find out on the web. [Introducing the Knowledge Graph: things, not strings]
The phrase ‘things, not strings’ is telling.
One of the added values of library descriptive practice has been that it provides structured data about the ‘things’ of interest in a body of literature: authors, works, illustrators, places, subjects, and so on. A major motivation for library linked data is to more widely release that value and to make those ‘things’ more discoverable, referencable, and relatable on the web – in ways in which other services can build on. An important aspect of this is to link the ‘things’ established in library resources to ‘things’ established in these emerging webscale knowledgebases. If this does not happen, library resources will be less valuable and the library contribution may be overlooked.
Viaf is an example here. It synthesises data about people – their names and bibliographic contexts – from multiple national libraries and makes it available in a way that makes an identity readily referencable:
Paul Muldoon
We provide a lot of contextual data, including links to different names, creations, and so on. And we relate it in various ways to other resources, including Worldcat, Wikipedia, some national library authority files, and so on. And links to Viaf are appearing in other places, including Freebase.
We hope that this ‘relatedness’ will become richer, but also that applications will begin to exploit the referencability and relatability we and the participating national libraries are providing.
Related entries:


