Article Title: "The (Digital) Library Environment: Ten Years After"
Author: Lorcan Dempsey
Publication Date: 08-February-2006
Publication: Ariadne Issue 46
Originating URL: http://www.ariadne.ac.uk/issue46/dempsey/
Buzz
data software framework wiki api html database wireless portfolio rss portal infrastructure archives metadata firefox digitisation standardisation tagging browser vocabularies schema blog repositories copyright flickr preservation oai-pmh cataloguing z39.50 visualisation cache aggregation e-learning copac ontologies personalisation vle openurl curation dspace sru eportfolio itunes crm e-research rae authentication uportal url taxonomy research netvibes
Citation
Introduction
We have recently come through several decennial celebrations: the W3C, the Dublin Core Metadata Initiative, D-Lib Magazine, and now Ariadne. What happened clearly in the mid-nineties was the convergence of the Web with more pervasive network connectivity, and this made our sense of the network as a shared space for research and learning, work and play, a more real and apparently achievable goal. What also emerged - at least in the library and research domains - was a sense that it was also a propitious time for digital libraries to move from niche to central role as part of the information infrastructure of this new shared space.
However, the story did not quite develop this way. We have built digital libraries and distributed information systems, but they are not necessarily central. A new information infrastructure has been built, supported by technical development and new business models. The world caught up and moved on. What does this mean for the library and the digital library?
In this article I will spend a little time looking at the environment in the early and mid-nineties, but this is really a prelude to thinking about where we are today, and saying something about libraries, digital libraries and related issues in the context of current changes.
Because, in a tidy calendrical symmetry, we are now again at a turning point. Ten years ago we saw the convergence of the human-readable Web with increased connectivity. This time, we are seeing the convergence of communicating applications and more pervasive, broadband connectivity. We are seeing the emergence of several large gravitational hubs of information infrastructure (Google, Amazon, Yahoo, iTunes, ...), the streamlining of workflow and process integration in a Web services idiom, and new social and service possibilities in a flatter network world. The world is flatter because computing and communications is more pervasive of our working and learning lives: we create, share and use digital content and services.
I focus on the UK, given Ariadne's scope, but will draw in other examples as appropriate. The Ariadne story, and the UK digital library story, mesh with the JISC story in various ways. The JISC development agenda brings together digital libraries, e-learning, and e-research, reflecting the broad entry of academic activities into a network space over this time. One of the main stories of this period is how the library will develop to support changed research and learning behaviours. As I am focusing on libraries, I will discuss these changes in the context of their impact on the library.
Here is how this article develops: I talk about the library environment ten years ago; this includes a look at the digital library programmes of the time. Then I spend some time talking about the environment in which libraries now have to work, before looking at the current library situation and some trends. Finally, I return to some thoughts about 'project' working, leading up to a brief conclusion.
Yesterday: A Decade Ago
A New Foundation: The Programmatic Perspective
Our early sense of digital libraries or virtual libraries or electronic libraries was heavily influenced by several funding programmes. In the early and mid-nineties, the sense of digital library potential received programmatic amplification through funded initiatives within the European Union, through the Digital Library Initiatives of the NSF in the US, and, here in the UK, through the Electronic Libraries Programme of JISC, colloquially known as eLib. Because of their foundational nature these programmes were more visibly momentous than their many successor initiatives: they galvanised the discussion about the electronic library, they created high expectations for change, and they corroborated with a flourish the growing recognition that living in the network world was going to be different. We are now used to thinking about 'grand challenges'; these were 'grand responses' [1][2][3].
The planning for these programmes began several years before the decade of interest here. The first EU call for proposals in the libraries area was as far back as July 1991. The motivating framework for this and later calls was established in the Libraries Action Plan, a document first circulated in 1988. A further Libraries Work Programme was developed in 1994. The Follett Report, which released the funding for eLib, was published in 1993, and eLib had calls for proposals in 1994 and 1995.
These programmes had very different emphases and motivations. The NSF digital library initiative had a research focus. The EU Libraries Programme aimed to facilitate change, but was spread across many European countries. The impact of eLib was felt very strongly in the UK. What they shared was a competitive project-based approach, remorseless generation of acronyms, and a pre-production focus. It is difficult to assess their impact, except to say that it is diffuse. Of course, one could point to some specific outcomes. Certainly, Index Data and Fretwell Downing Informatics participated in EU and JISC projects, and some of their products are influenced by that participation. One might wonder to what extent eLib project funding supported some of the product development in BIDS (Bath Information and Data Services) that later showed up in Ingenta. EU projects certainly supported some of the intellectual work on formats and protocols, for example in early EDI (Electronic Data Interchange) work between libraries and the book trade. Further exploration of this question is not my purpose here, however interesting it might be. These programmes definitely provided learning opportunities for involved staff, and a general frame of reference for community discussion. What I will suggest though, and return to below, is that this project-based focus is a very inefficient way of achieving systemic state-of-the-art change, a goal that the EU and JISC, with their more applied focus, certainly have. Chris Rusbridge interestingly contrasts the 'development' focus of eLib with the more research focus of the DLI projects in a D-Lib article discussing 'the hybrid library', a term he originated [4]. The later NSDL programme from NSF shows more of this 'development' emphasis, as it aims to build services for education.
Reductively, one can identify two overarching and linked themes for much of this work, and, indeed, for much subsequent work in the digital library arena. The first I will call discovery to delivery (D2D). This looks at services which mediate access between a user and a distributed library resource, which streamline supply chains, and which focus on user-oriented process integration. Here cluster issues of resource discovery, linking, and requesting. Topics which have emerged over the years are search/metasearch, portals/brokers, federation, and, later, harvesting and resolution. There has been much work on metadata formats and protocols for search and request. Some of this activity built on earlier work. For example, in the early nineties there was a strong EU focus on OSI (Open Systems Interconnection) and on developing an OSI protocol framework for library applications. Certainly, a major issue for EU- funded projects was the move away from OSI and towards the Internet and its associated protocols. This activity saw the emergence of several niche library protocols, notably ISO-ILL and Z39.50, developed in an OSI framework [5]. This probably limited their more widespread adoption later with significant implications for the development of distributed library systems. One can also note a focus on metadata, and exploration of a range of approaches, notably Dublin Core, initiated in 1995 [6].
The second theme is repository and content management, where the dominant emphasis is on managing large repositories of digital content, and on making it available in various ways. This emphasis developed later, evolving alongside the growing availability of digital materials whether those were born digital or reborn digital (converted from another format). A more recent interest, then, is integrating emerging repository infrastructures with the evolving discovery to delivery apparatus. This is in line with the trajectory in this period from a focus on metadata (as the materials of interest were still largely print) to a focus on full-blown digital environments.
Chris Rusbridge's hybrid library article charts the interests through Phases 1 and 2 of eLib and into Phase 3. Phases 1 and 2 focused on electronic publishing, learning and teaching (on demand publishing and electronic reserve), and access to resources (subject gateways and document delivery), as well as on training and awareness, and on some supporting studies. Phase 3 focused on the hybrid library as an integrating strategy, and on digital preservation (these two strands echo the D2D and content management emphases I mention above).
So, it is interesting that these initiatives were planned before the real emergence of the Web, that they spoke about a need to find shared ways of addressing needs in a time of real change, and they established a project-based funding culture. Interestingly, the Follett Report - which motivated eLib - does not mention the Web at all. They highlighted the challenge of designing and building new services, and they galvanised discussion of what virtual, digital, or electronic libraries were.
I was closely involved with the EU and eLib programmes, as a programme and call drafter, evaluator, bidder, project reviewer and project participant. I had little direct involvement with the original NSF programme, but had some later contacts at project and programme level. Looking back, I take away five things from these foundational programmes, particularly from the eLib and EU programmes:
- They were major learning experiences for participants, many of whom have gone on to do important work in the library community.
- They showed that the development of new services depends on organisational and business changes that it is difficult for project-based programmes to bring about. This is a continuing issue.
- Many of the assumptions about technical architecture, service models and user behaviours in emerging digital library developments were formed pre-Web. In particular, we have become accustomed to a model within which presentation, application and data are tightly integrated. This restricts data flow and system communication leading to a silo environment which looks increasingly at odds with our flatter network world. The distributed approaches developed in this period have not been widely adopted in end-user services: they have a B2B pre-webby feel and are mostly used in that context.
- Their impact has been diffuse and indirect, and is difficult to assess. Compared to the overall number of deliverables, there is a small number of ongoing products or services which are direct project outcomes. In fact, many of their goals have been moved forward independently in the commercial sector. See, for example, current developments in metasearch and the collections of digitised historic materials which are available commercially.
- How does one transfer innovation into routine service? Certainly, alongside the project work there was service innovation in the JISC environment, but it flowed from central planning.
Libraries Yesterday: Libraries, Networks and Services
What about actual library services and organisation during this 'digital library decade'. Think system-wide and think local.
System-wide, there was an ambition to achieve systemic change in how information services were provided as part of the wider provision of research and learning support [7][8]. Infrastructure was developed at various levels to help create system-wide efficiencies. This included a national authentication system, several data centres whose remit was to consolidate hosting of data and services, and also caching and mirroring services. We also saw consolidated procurement, management and delivery of information services at a national level. Some of these were licensed third-party databases, made available through the data centres, and some were research materials curated at discipline-specific data services. Resource discovery services were also put in place, through the subject gateways which went on to become the Resource Discovery Network, and through COPAC, the CURL union catalogue which began to receive central funding. The Archives Hub was added later. The full range of JISC services is impressive and is looked upon with a mixture of bemusement and envy from elsewhere. Bemusement because of the ever-changing tangle of committees, projects, people, programmes, and acronyms. Envy because of the ability to mobilise collective resources to identify and achieve system-wide goals. One advantage of this approach is that it is a good way of securing infrastructure, an issue that is problematic for environments without this centralised capacity for decision-making and deployment. Of course, this infrastructure has national boundaries, which will be more of an issue as we move forward. Service registries provide an example of where it would be good to have international coverage.
At the institutional level, change was more evolutionary than some of the programmatic rhetoric might have suggested. Systems investment continued to focus on the 'integrated library system'. The move to more openly available abstracting and indexing services, and then electronic journals, proceeded apace, with support from several JISC initiatives. The introduction of a shared authentication system in Athens greatly facilitated access to this licensed resource, and created an environment in which publishers and vendors were more comfortable with national deals. Digital content management initiatives were generally not large scale, and, as noted above, outside some commercial offerings we have seen little large-scale aggregation of digital collections. It is not until quite recently with the introduction of resolution and metasearch services that machine-to-machine services achieve any prominence in general library activities. At the same time, there was a general updating of interfaces to the Web environment, but databases remain siloed behind these interfaces. The common pattern of provision becomes one of multiple Web sites, each relatively standalone with its user interface. And as I discuss later, this remains the dominant delivery mode, which is increasingly problematic when library users have so many places where they can spend their 'attention'.
Today: The New Environment
Let us now fast-forward to the present. How is the world different at the end of the decade?
We know that academic libraries are not ends in themselves: they support the research, learning and teaching missions of their institutions. Libraries must co-evolve with changing research and learning behaviours in a new network space. We tend to focus on the impact of technology on libraries, however the real long-term issue is how technology will influence how library users behave and what they expect.
Here I try and characterise some of the ways in which change in the current environment will affect library responses. I focus on general systems trends, on the emergence of information infrastructure around long tail aggregators, and on changing user behaviours and patterns of research and learning.
Systems in the Webby World
Three broad topics occur to me as I think about systems in the network world. Here is a summary:
Flat Applications and Liquid Content
We are moving to a flatter network world, where the gap between the Web and business applications is narrowing. Applications are working over the Web. Data is flowing more readily into user environments. Web services and RSS are important parts of a spreading connective tissue which allows users to compose services in different environments. In this context, workflows and business processes are being further automated, data is more accessible and malleable, and applications may be more flexibly built and reconfigured from components. Closely related is the emphasis on open source and on-demand services. Examples here are services like salesforce.com [9] (the poster child of the on-demand software phenomenon, it provides Customer Relationship Management services) or WebEx [10] (a conferencing and online meeting provider). The idea here is that rather than installing local instances of an application (CRM or conferencing/meeting management in these two cases respectively) an organisation can use a central, Web-based application. Potential advantages are lower cost of ownership, less risk, and smoother and more frequent upgrade. Potential disadvantages include less local customisation and flexibility.
More processes are data-driven. Activities shed data, and this data is being consolidated and mined for intelligence to drive services and decisions. Of course, significant applications are still being built, but the ways in which they are articulated and woven into the world of work are changing. At the same time, content is being unbundled and recombined. Think how we manage photographs, or music, or TV programmes as pieces which can be recombined: in albums, in playlists, in slideshows, across personal and hosting sites [11].
New Social and Service Affordances
Flat applications and liquid content create new opportunities. Think of three things.
- Workflow and process standardisation allows organisations to think about how best to source activities, perhaps outsourcing some activities so as to concentrate on where they most add value. Organisations are moving away from needing to integrate all their operations vertically. One way of thinking about this change is to note a progression from database, through Web site/portal, to workflow as the locus of interaction with the Web. This is a natural consequence of moving more activities on to the network. New support structures need to be created and these in turn reshape organisations and their activities. Thomas Davenport describes how this trend is forcing organisations really to focus on what is distinctive about what they do, and source what is less central externally, perhaps even sharing capacity with their rivals [12].
- Second, flatter applications and liquid data allow greater collaborative working, maybe through sharing of components, collaboratively sourcing shared activities, or working on shared problems. Platform services, which consolidate particular functionality or data, may be used by many other applications to build value. Major network services such as Google, Amazon and eBay, are at once major gravitational hubs for users but are also increasingly platforms upon which others build services.
- And finally, we are seeing a great upsurge in social networking services, where a flat connective tissue based on blogs, wikis, IM (Instant Messaging) and other tools create social and communication spaces in which new services are being built.
New Business and Organisational Patterns
Business models and organisational structures are co-evolving with the technical developments and new services that they allow. Again, think of three topics here, which flow from the points made above.
- The first is the way in which information resources are flowing onto the network, free at the point of use or available for a small fee. Google is an intelligent ad placement service: its revenues are overwhelmingly from this source. It has recently moved to establish a similar role in radio. The more people use Google to find things, or the more people use other services where Google places ads, the better it is for Google. Fuelled by this, we are seeing more and more content flow onto the open Web, and, correspondingly, users increasingly expecting to find resources of interest 'on Web', where on-Web means being found in one of the major search engines. Materials that are 'off-Web' are visible only to the persistent user. We have to see whether more sophisticated 'vertical' services emerge, which cater for more specific needs, but for the moment the search engines and other large presences are major hubs.
- On-demand and platform services supported by automated workflows and process standardisation are becoming more viable options. In his book, The World is Flat [13],Thomas Friedman charts how these developments are driving business change. Increasingly, organisations will focus on their strengths, and rely on horisontally specialised third parties for common services. (Think of how UK Universities rely on a shared authentication service.)
- This continued interdependence in a flatter world means that services are increasingly co-created, and this co-creation is extending to the relationship between a service provider and its users. Think of eBay which provides an infrastructure to bring sellers and buyers together. Indeed we see a growing experimentation with such co-creation models whether in the form of user-contributed content on Amazon or in various of the social networking services.
Information Hubs, the Long Tail and Attention
A distinctive feature of the latter part of the decade has been the emergence of major Internet presences with strong gravitational pull [14]. Think Amazon, Google, Yahoo, eBay, iTunes. These services have been developed in a Web environment, and some of their characteristics are:
- Comprehensive: They offer the user a sufficiently encompassing experience that they need go no further, or do not believe that they need to go further. Google or Amazon searchers, for example, may believe that they have prospected the full Web, or all the books in print, and even if they do not, they are often disinclined to expend the additional effort required to look elsewhere.
- Integrated D2D: They are interested in fulfilment, in ensuring that users leave with what they want. This means that they integrate services for location, request and deliver into the original discover experience. On the open Web, this is a matter of minimising clicks. For other services, it means building appropriate supply chain and workflow support. So, for example, if you buy something from Amazon, they will try to manage your transactions to fulfilment, and try to keep you informed about progress. In the background, they have worked hard on the infrastructure necessary to reduce the transaction costs of the discovery to deliver chain, in terms of how they efficiently manage and deliver inventory, in terms of online payment for services, and in terms of trust mechanisms.
- Making data work hard: They collect data about use and usage and adapt their services based on this. There are interested in enhancing your experience, and your connection with them. Think of how Google and Amazon reflexively use data to modify the service, whether in personalisation features, page ranking, or targeted advertising.
- Horizontal: platforms and interfaces. One issue for these services is that they are 'horizontal' in the sense that they cater for a broad undifferentiated interest. They attack this through engagement, allowing some individual customisation. They have explored ways in which they extend their reach by being available in forms which support integration into other workflows. This may be in the form of toolbars, APIs, RSS feeds and various other affiliate and partner programs. Their Web interface is important, but it is not the only place that they will rendezvous with their users. They also allow vertical services to develop on top of their APIs, and this model is likely to continue as these services become background platforms driving many foreground services. Over time we may see these services deliver much more of their value in other people's applications, which are more targeted to particular needs. Think of the variety of ways in which Amazon data and services are available.
- A co-created experience. Many large Internet presences involve the user in the creation of the service or in their own experience of it. Each is leveraging a growing amount of data to create additional value. This may be user- contributed data, as with Amazon reviews or eBay ratings, or data that is collected by the services about resources and about user behaviours and preferences.
These services recognise that they need to fight for the attention of the user. And they are important case studies of what Chris Anderson has called The Long Tail [15]. The argument is about how the Internet changes markets. In the 'physical world', the costs of distribution, retail and consumption mean that an item has to generate enough sales to justify its use of scarce shelf, theatre or spectrum space. This leads to a limit on what is available through physical outlets and a corresponding limit on the selection potential of users. At the same time, the demand for a particular product or service is limited by the size of the population to which the physical location is accessible.
These Internet services have two important characteristics which alter the dynamic of markets. They aggregate supply, and they aggregate demand. I noted above that Google is a massive ad placement service. What does Google do? Google services the long tail of advertising - those for whom the bar was too high in earlier times of scarce column inches or broadcast minutes. And by aggregating demand, delivering a large volume of users, they increase the chances of the advert being seen by somebody to whom it is relevant. This matching of demand to supply is supported by their use of data. Think of Netflix: it aggregates supply as discussed here. It makes the long tail of available movies visible for inspection by potential viewers. However, importantly, it also aggregates demand: a larger pool of potential users is available to inspect any particular item, increasing the chances that it will be borrowed by somebody.
Again, it is interesting to think of library services against this background, repeating some of the topics mentioned above.
Aggregation of supply and demand. Aggregation of supply involves comprehensive discovery and low transaction costs in the D2D chain. Aggregation of demand involves making sure that resources are 'discoverable' by anybody who may have an interest in them. Despite many years of activity the library resource is fragmented - both within the library, and across libraries. The links between discover-locate-request-deliver are still intermittent, and it may not be possible to track the status of an item easily. Think of the UK Higher Education system for example: there is no comprehensive union catalogue, and resource-sharing infrastructure is fragmented. Non-appearance on the Web, or in user environments, means that demand may be less than it could be. Together these factors suggest that library resources are not being provided in a way that exploits the changed network model of information discovery and use. The long tail is not simply about having a lot of material: it is about ensuring that that material is readily discoverable and accessible, and that it is seen by those who need to see it.
Making data work hard, engagement and co-creation. Data is inert in our systems. We do not release the investment in structured data in engaging and interesting user experiences. We are seeing signs that this is changing, but it has taken some time. Nor do we make much use of 'intentional' data, data about choices, use and usage, to refine and manage services. Holdings data, circulation data, database usage data, resolution data: much more could be done to mine this for intelligence about how to develop services. Think of services like 'people who borrowed this, also borrowed that' for example.
Platforms and interfaces. Libraries present an interesting case here. In some ways, the library community is very advanced, as it needs to be as a 'broker' organisation. It has developed an ecosystem of resource sharing which is supported by shared cataloguing platforms, messaging and delivery systems. It is accustomed to depending on others for service, and, indeed, cataloguing is an early 'co-creation' model. However, more recent distributed library development has so far not resulted in similar organisational evolution. I think that such evolution is very likely as libraries move other operations into shared platform services which serve many organisations (for example, is there any value in shared knowledge bases or Electronic Resource Management approaches?). I return to this topic later. In fact, the library composes many of its services from an array of external providers. However, in the network world it is struggling to fit many 'silo' services into metasearch or Web environments. The library presentation to the user or to the user applications remains locked within a particular human interface. It is also not always straightforward moving data in and out of library systems. So, it is difficult to place library resources at the 'point of need' in the other places their users are.
These topics all have an important bearing on attention. An important question facing libraries is how to build services in an environment where content is increasingly abundant, where the costs of production and distribution are declining, where the preferred modes of interaction and engagement with research and learning materials is changing. Where, crucially, attention is scarcer. The current academic library is a construct of a time when the production and distribution of research and learning materials was restricted to a few channels, and where there was less competition for the attention of potential library users. Some things you just had to go to the library for. In the current Web environment, this is no longer the case. There are many demands on attention and many resources are available. We see several approaches emerging. There is an increased interest in marketing in libraries, even if it is not called this. Related to this, the library 'offer' needs to be clearer, and we see renewed attention to how resources are presented, moving away from long lists of databases for example. And, as I have been discussing, we see a growing discussion of how to engage with user environments and workflows.
Where attention is scarce, the library needs to provide services which save time, which are built around user workflow, and which are targeted and engaging. This means that the library will have to shape its offering in the digital environment more actively. Aggregating resources may not be enough. They will be shaped and projected into user environments in ways that support learning and research objectives. For example, how do you tailor network resources for particular courses or for particular technical environments (RSS aggregator, courseware management system)? How do you make resources visible in search engine results? How do you provide links back from other discovery venues to the library, so that the user can actually get the resource of interest? How do you support metadata creation, document deposit, or research assessment reporting?
User Behaviours: The Changing Patterns of Research and Learning
In a flat network world, where data and content flow more freely, much of what might have happened in the library is pushed out into network user environments. And a variety of other services have emerged to support network management and use of learning and research materials. This raises three interesting issues which I touch on here. The first is that remixing, of content or of services, becomes an integral part of routine personal activity on the network. This in turn raises questions about workflow and curation, as the available personal, institutional, academic, and consumer choices multiply. Think for a moment of the impact of Flickr or iTunes here. In each case, they offer 'consumer' services, and because of their centrality to how people use and manage their resources, they are being integrated in various ways into university and library offerings [16].
The network evolution of research and learning practices across disciplines and institutions is something that we need to know more about it. Libraries need to understand how best to co-evolve with these changes, and need more evidence upon which to base their planning. For example, Carole Palmer has been doing very interesting work looking at practices in humanities and biomedical research, and thinking about how those in turn influence research library services [17]. She points to new types of scholarly resource, new ways of prospecting the scholarly record through digital resources, and new support needs as researchers work with digital applications and data. This type of work goes beyond looking at how people are using library resources to suggest what requirements will emerge from their changing behaviours.
Remixing and scholarly work. In Raymond Yee's words, we increasingly want to 'gather, create and share' resources [18]. This means resources need to be accessible to manipulation, to be locally managed, and to be recombined and transformed in various ways. We need to be able to pull disparate resources into custom collections. These may be content resources, or, increasingly, services, where a user can manipulate and connect functionality from different places. Persistent linking, RSS feeds, and simple protocol interfaces become important. We do not currently have a widely used 'service composition framework' which allows users to pull together resources easily in a work environment. Toolbars and FireFox extensions are current examples of simple service composition. Arranging services in my.yahoo is another. Resources may be sourced from personal, institutional and third-party environments. We are developing an extended collection vocabulary: playlist, blogroll, slideshow, dataset. Tools for manipulation, analysis and visualisation are becoming a part of routine behaviour for many.
And of course, the reuse of materials in the gather, create, share model presents an issue for many library-supplied materials given the restrictions that there may be on some of this material.
Workflows. Historically, library users have adapted their workflow to the library. As the network becomes more important, libraries need to adapt their services to the network workflows of their users. Think reductively of two workflow end-points [19].
The first is demand-side: we are constructing flows and integrating resources in our own personal spaces. We are drawing on social networking sites, blogs, RSS aggregators, bookmarklets, toolbars, extensions, plug-ins. Some people may be developing elaborate digital identities, a personal 'bricolage' of network services. Others are less actively constructive, working with what comes straight out of the box. However, whether built into our browser or available from a growing number of network services, we will increasingly have rich demand-side flow construction and resource integration facilities 'straight out of the box', more mature 'service composition frameworks'.
The second is supply-side, where workflow and integration have been pre-fabricated to support particular tasks. Think of a course management system, or a lab book application, or how a depositor interacts with an institutional repository, or an e-portfolio, or a collection of research support services such as those provided in Community of Science.
One reason that supply-side customisation and personalisation services have not been more actively taken up is that it may be less important to me to be able to manipulate flows and resources within a pre-fabricated supply-side environment than to be able to integrate them into my self-constructed demand-side environment. So, for example the most important thing for me may not be to manipulate components within a portal interface, or to have email alerts sent to me, it may be to have an RSS feed so that I can interact with a range of resources in a uniform way. Or I may prefer to add stuff to my My.Yahoo page, if that is the place where I compose my digital landscape. The value may be adapting to my preferred 'composition framework' rather than asking me to use yet another one elsewhere.
What does this mean for libraries? Libraries need to think more strongly about how to project services into those workflows, and the 'composition frameworks' that support them.
Many of our recent discussions have in fact been about this very issue, about putting the library in the flow. Think of the course management system. If this helps structure the 'learnflow' then the library needs to think about how to be in that flow. Think of Google. It has reached into the browser and the cellphone. It is firmly in the flow of user behaviour, and as libraries and information providers want to be in that flow also they are discussing how best to expose their data to Google and other search engines. Think of the iPod. If this is the preferred place to manage my liquid content, what does this mean for library content? Think of the RSS aggregator: if I structure my consumption around this what does this mean for stuff that is not available as a feed?
Here are a couple of examples: one in a 'research' context, one in a 'learning' one. For the first think of institutional repositories. The institutional repository is a set of services for researchers. It may have a number of goals: support open access, curate institutional intellectual assets, centralised management of research outputs, preservation, and so on. What seems likely to happen is that what is now called the institutional repository will be a part of a range of services which support the creation, curation, and disclosure of research outputs. We can see how its role is being extended to support workflow better. Consider this account from the University of Rochester which seeks to understand research work practices as a basis for further service development [20].
In the long run, we envision a system that, first and foremost, supports our faculty members' efforts to "do their own work"--that is, to organise their resources, do their writing, work with co-authors, and so on. Such a system will include the self-publishing and self-archiving features that the DSpace code already supports, and will rely heavily on preservation, metadata, persistent URLs, and other existing features of DSpace. When we build this system, we will include a simple mechanism for converting works in progress into self-published or self-archived works, that is, moving documents from an in-progress folder into the IR. We believe that if we support the research process as a whole, and if faculty members find that the product meets their needs and fits their way of work, they will use it, and "naturally" put more of their work into the IR.
Looking forward we might surmise that future success will be more assured to the extent to which the new support is a natural extension of current workflows.
In a UK context, look at the IRRA (Institutional Repositories and Research Assessment) project which is exploring how institutional repositories might be extended to support some of the recording and reporting needs of the Research Assessment Exercise. Again, this is looking at broadening workflow support, which in turn should make the institutional repository more valuable [21][22].
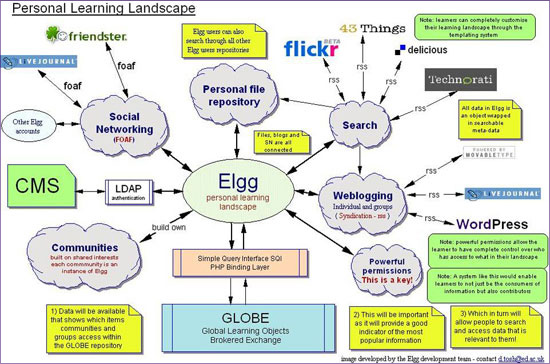
A learning example comes from a presentation by David Tosh and Ben Werdmuller which draws on their work modelling 'learning landscapes' in the context of the evolution of e-portfolios [23] (see Figure 1 above). They see the e-portfolio as a place where the student constructs a digital identity, which connects resources, experiences, and tutors. Connection is important, because learning happens in contexts of communication and exchange beyond the formal course structures. The VLE (Virtual Learning Environment also known as a course management system) which, in the terms presented above, is a supply-side workflow manager, is one part of this landscape. A focus of this work appears to be to develop capacity for richer demand-side integration. Now, I think this has nice illustrative value for a couple of reasons. One, the 'library' is not present in this iteration of the landscape. But, more importantly, how would one represent the library if it were to be dropped in? As 'the library'? As a set of services (catalogue, virtual reference, ...)? If as a set of services, which services? And, if a particular set of services, how well would they 'play' in this environment? What would need to be done for them to be in the flow?
Curation. As the creation, sharing and use of digital resources becomes central to research and learning, so does curation.
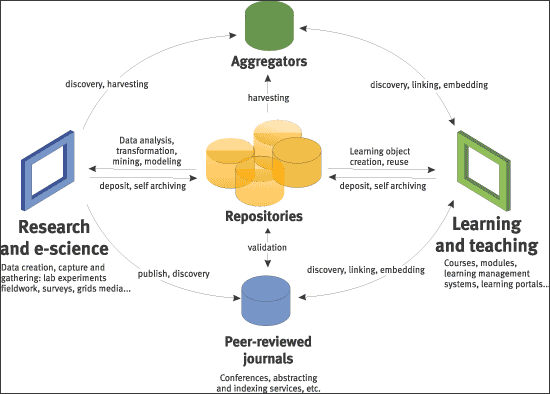
Think of the data-intensive nature of modern science, of the accumulation of learning materials, of personal and institutional records, of digitised collections. Data is flowing through multiple professional, institutional, and personal circuits, which have yet to be institutionalised in a set of university responsibilities. Figure 2 below shows a schematic of flows of research and learning materials [24].The nature of infrastructure necessary to support these resources is being investigated, as are the services that will help users get their work done effectively. We are really in the very early stages of working through what it means efficiently to manage this range. What does seem clear is that much of this activity is unsustainably expensive given the lack of common metadata approaches, the redundancy of server and development resources, and the hand-crafted nature of much activity. To what extent this activity can be supported by fewer systems and services is yet to be seen. In general, libraries face the challenge of domain specialisation, where particular disciplines will have different practices, metadata schema, ontologies and so on. What can be done to support institutional activity in terms of shared storage and preservation solutions, metadata creation and taxonomy tools which reduce overall costs? How does this fit in with broader systems of research support?
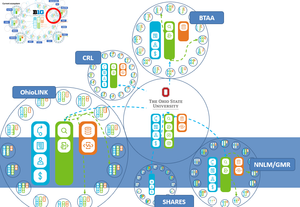
The UK has seen the emergence of several data services, some within the JISC world, some supported by the Research Councils. Presumably these will continue, and the balance between institutional role and data service will vary with the service.
Libraries Today and Tomorrow: The Challenge of Working in a Flat World
Figure 3 below shows the library at the centre of a flattened world. It needs to project its services into the user environment, and those services in turn rely on bringing together a range of other services and products. We can describe these two emphases in the context of the discussion so far. The library in the user environment is about how the library responds to changing network behaviours. It cannot simply aggregate resources. It has to configure them, and shape them to support research and learning activities that are also being changed by the network.
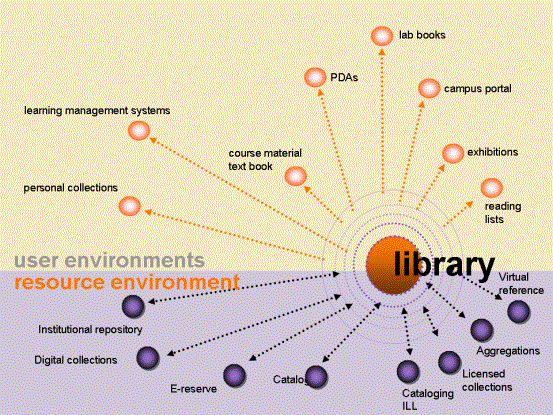
How the library organises its own capacities to provide services is also changing as the network becomes more central. Libraries, and libraries acting collectively, are thinking about how best to allocate resources, how to source new solutions collaboratively, and how to look for system-wide efficiencies.
Of course these two issues are related. The library needs to focus on its distinctive contribution, which, I would argue, is to create services which enhance research and learning experiences. To do this, it needs to routinise as much as possible the apparatus from which it creates services. Labour-intensive, redundant activities represent a serious opportunity cost for the library.
Of course, the picture is misleading in one sense: the library is one source only of materials for the user, it is not necessarily at the centre of their information world.
Delivering Library Services: The Library in the User Environment
I spoke about the evolution of library services during the digital library decade earlier. Where are we now, and how are we moving forward?
The integrated library system? The integrated library system (ILS) remains a central library investment, although one wonders how long this will continue in its current form [25][26]. The financial and operational burden of periodically transitioning such a monolithic system seems too high to sustain and is one incentive for disintegration of the ILS into more manageable components. Another is that the library is acquiring additional systems: the ILS is managing a progressively smaller part of the overall library operation. Another is discussion about how one might find other ways of sourcing some of the ILS functionality, especially in the context of broader institutional enterprise systems (ordering materials for example through the university-wide apparatus). The case of the catalogue is especially interesting, where there is a growing desire to provide a discovery experience in another environment (a standalone catalogue application with more features, from other databases, from Amazon, from reading lists or social bookmarking systems, and so on). In each of these cases, there is a need to connect the discovery experience back to the library system for further action (using a mix of COinS (ContextObjects in Spans), scripting and scraping techniques - all that is available at the moment). All these factors point to a reduced interest in the ILS per se, as it becomes more of a back-office application. And the library vendors are certainly competing around other components, which include a resolver, a metasearch application, an electronic resource management system, maybe an institutional repository, and other digital asset management systems. The existing library system is very much a silo application with limited data flow and interconnection. It sits as an inhospitable peak in the flat Web environment. Over the next while we will likely see this change. Service frameworks may not be clear now, but service and commercial imperatives will drive clarification.
Flattening silos. The silo nature of library systems becomes apparent when we try to present them in Web sites. They have not been developed as an integrated suite in a Web context. In fact, most library Web sites wrap a thin Web interface around a set of systems which have not been built to talk to each other or to emerging user environments. The user experience is driven by the systems constraints and arbitrary database boundaries which reflect a supply-driven service. Consider the long list of databases that is often presented to the user: how do they know where to look? Resolution services have been a major innovation in creating linkages. Recently there has been a strong focus on metasearch to try to overcome some of the fragmentation of supply, and respond to demand-driven requirement for consolidation. But, there is a growing awareness that metasearch is a partial solution only, and perhaps not best offered as a one-stop-shop search-all interface. Again, we will see this improve over time, but there are major structural and business issues. For example, why should the library discovery experience be split across so many databases (catalogue included) which may mean little to the user? Is there merit in pooling resources in larger data reservoirs, rather than going through the multiplied local cost and effort of metasearch?
Creation to curation. I have discussed how the creation, organisation and curation of resources by users creates new service opportunities and issues for libraries. There are issues of creating services which fit into a variety of user workflows, of supporting learning and research remix behaviours, and of providing curation support. The challenge is that the support required potentially stretches across the full research and learning lifecycle as, albeit variably, more of this activity is coming onto the network in different ways. And it stretches across very different modes of behaviour and requirement from curation of large datasets; to advice about resource creation, analysis and exposure; to metadata creation and repository services; to copyright advice; and so on. Take just one example: various commentators see the emergence of the Thematic Research Collection as an important new scholarly genre [27][28]. Scholars at the University of Virginia have pioneered this approach, and several deep archives support focused investigation of particular topics. Examples include the Rosetti Archive [29] and the Valley of the Shadow [30], an extensive documentary record of two communities during the American Civil War period. If this becomes a common mode of scholarly production, what support should the library provide?
The new bibliography. Reading lists, citation managers, and emerging social bookmarking sites are all places where data pools. This data reflects choices, recommendations, intentions. They provide interesting sites of intersection: between personal workspaces and available resources, between libraries and learning management systems, between the individual and the group. I include this note here because I think that they are underrated sites of integration and connection. Think of what might happen if Microsoft Word allowed you to format references in a document in a way that they could be exported in a structured format, say including COinS.
Contribution and communication. A notable trend discussed above was the growing importance of user participation, in the form of tagging, reviews and annotation. How this might be accommodated in library services is a question that has only just begun to be explored. Again, there is probably merit in looking at this activity at some aggregate level for scale reasons.
The long tail. And finally, we face the large issue of what arrangements are best to unite users and resources in a network environment. The library offer is fragmented within the library. The library community itself is imperfectly articulated in terms of the discover-locate-request-deliver chain. The fragmentation of the discovery experience and the transaction costs of using library resources - whether local or system-wide - require the user to spend more of their scarce attention if they want to make best use of them, an expense many are increasingly less prepared to incur. Just as supply side aggregation is limited, so is demand side aggregation. Typically, library services are only seen by the audience which makes its way into the library Web presence and finds what they are looking for. The resources are not visible to the many other people who may find them valuable. This is one reason for wondering about exposure to the search engines or emerging vertical services like Google Scholar, or being better able to link people back from other discovery venues to the library. The library offer is largely 'off-Web'. This is further discussed in the next section, as it is an area where shared solutions are required.
Much of this is about how targeted services can add value, saving the scarce time of the user and creating value at the point of need. Some of it can be achieved within an institutional context; some of it relies on system-wide development.
Logistics and Consolidation: System-wide Efficiencies
The burden of much of what I have been saying is that there is benefit in consolidation at certain levels, to remove redundancy and build capacity. It is not possible for libraries individually to address many of the issues identified in the last section and throughout this paper. Solutions depend on systemic or shared approaches. Libraries are very used to this type of activity. Over the years they have given more of their activities over to 'the network'. Think of cataloguing for example, or more recently of experiments with virtual reference. Think of how they have moved to a 'rental' model for the journal literature (for good or ill).
Historically, the British Library Document Supply Centre represented an important consolidation of resource in the UK which provided an effective back-up to individual libraries. Interestingly, the BLDSC was set up to consolidate inventory and minimise distribution costs. It was a long tail aggregator before the term existed: an organisation devoted to library logistics. It aggregated supply, and perhaps its effectiveness meant that the UK union catalogue and resource-sharing apparatus is less well developed than in some other countries. I have already described how the UK has also benefited from some consolidation of services through the activities of JISC, which has created system-wide efficiencies through central provision of networking, authentication, purchasing, hosting and other services. Effectively, JISC and British Library services have removed redundancy from library activities and built shared capacity.
Interestingly, the 'traditional' resource-sharing infrastructure is becoming more important again. We moved through a period where more distributed approaches were discussed and explored, but the pendulum seems to be swinging towards consolidation again. Think of two looming issues for the academic library for example: mass digitisation and off-site storage of print materials. In each case, an effective response depends on available data about the composition of collections, about overlap between collections, about distribution of rare or unique items, about disciplinary or format distributions, about demand for materials expressed through circulation or interlibrary lending traffic. Think of preservation of book and journal literature. Again, there is a dependency on shared data which may not be there. Making these types of decisions without consolidated data will be difficult.
Developing services in the network environment suggest other ways in which libraries may benefit from consolidation and sharing. Here are some examples related to a UK Higher Education context. For convenience of discussion, I cluster them under discovery to delivery and creation to curation.
Here are some areas where collective attention might better support discovery to delivery in the network environment:
A unified discovery experience. Think about this range of materials under library management: books, journals, cultural heritage materials, research and learning outputs, Web resources. What about a union catalogue for books, a consolidated articles database which reduces the cost of local metasearch, a harvest of institutional repositories? Each of these would involve a different approach, and there may be merit in thinking of them together. Whereas the rationale may be to support discovery, other uses follow from having this consolidation: comparative collection analysis for example. A service which collects and further exposes metadata in institutional repositories is an incentive to academic staff to deposit materials. There are several consolidations of article-level metadata: would it be possible to create a resource which would actually meet a large part of local needs? This consolidation also provides a potential point for collection of user-contributed tagging, reviews, and so on.
Syndicating the discovery experience. A consolidated resource might be a Web destination itself. However, it can also be used in other ways, as a platform in the way that was discussed above. There are several services one can imagine here. Exposing the data to search engines and other services is one, and I come back to that when talking about service routing in a moment. Offering subject or regional views is another. Offering 'alerts' for new or relevant materials is another. This may be made available in ways in which it can be surfaced in local environments: RSS feeds and various protocol interfaces.
A service router: extending the discovery experience. If libraries expose data to search engines individually, various issues emerge. How do you match just the library resource to just those users who are entitled to use them? Unless, the search engine does consolidation you will end up with masses of redundant data being indexed. This suggests the benefit of a switch or router, which can connect users to relevant resources when they find something. There are various ways in which you could do this. And, of course, going beyond this, one does not only want to discover information objects which may be in a library, one may want to use other library services: virtual reference, a resolver (behind the scenes), interlibrary lending, and so on. This requires some description of these services, and a way of having the user rendezvous with them. Again, one could imagine various ways of doing this. (This service routing model is a part of OCLC's Open WorldCat approach. At present, a user who finds a WorldCat record in a participating search engine is directed to a 'rendezvous' page. More services may be offered there [31].)
Reducing transaction costs: Wherever libraries want to work collectively there is an infrastructure issue. One wants to lower the transaction costs of the shared activity, to make it affordable and provide an incentive to use it. So, for example, infrastructure is needed to reduce the need for user-initiated connections between stages on the discovery-locate-request-deliver chain. For example, the OpenURL is a major piece of infrastructure here and Resolver Registry services are emerging in the UK and elsewhere. More generally, such chains can be hardwired. However, increasingly, one will want to allow different combinations to be articulated in response to particular need which will depend on 'intelligence' in the network in the form of registries of services, policies, and so on. Such infrastructure may be provided in various ways. Think also of a virtual reference network - if this is to work effectively, there needs to be management of the support infrastructure. These activities involve transactions, which need tracking to support audit, fee adjustments, and so on. Perhaps, a PayPal-like solution for the academic community!
Refining service through feedback. We have holdings data, circulation data, database usage data, resolver data, download data, and lots of other data which tells us things about preferences, intentions, choices. And which can in turn be used to improve services by providing feedback, or by being used to provide recommender and filtering services. There is value in aggregating such data, and in managing it to create value-added services.
And here are some examples of how collective approaches might help creation, organisation and curation.
Data creation and management. Libraries have various approaches to creating and sharing bibliographic data. Newer systems have created new data requirements. For example, libraries are investing in knowledge bases, and are beginning to consider Electronic Resource Management systems. These systems are populated in various ways. What options are there for reducing the cost of this activity through consolidation?
Storage and preservation. It may not make sense for every institution to invest in a complete storage and preservation solution. One could imagine the ability to save resources to a shared storage substrate with defined preservation capabilities. The articulation of local, centralised and replicated approaches is an area where collective strategising is needed.
Print content distribution layer. On the network a 'content distribution layer' may consist of caches, mirrors, redundant servers which ensure efficient distribution of digital resource and effective use of network resources. Interestingly, we may be moving to a situation where we would like to see such a system for the print collections in our libraries. This system would consist of a co-ordinated repository and delivery framework [32]. As Chris Rusbridge notes in his article in this issue, the costs of storage and preservation of the collective print resource are high. Over time, we will probably see attempts made to reduce that cost by consolidating print collections and putting in place effective distribution mechanisms between repositories and points of demand.
On-demand system components. The library systems environment is becoming more complex, with a variety of components. Academic libraries are figuring out what to do with a set of systems which in some ways are immature and in development. The institutional repository is an example. Another is the creation of metadata across a variety of areas. Institutions are spending a lot of time looking at various metadata creation environments, developing schema, thinking about moving metadata about, thinking about taxonomies. Some of this could be provided as a configurable service. There is potential here for on-demand services.
It is clear that the above is far from a comprehensive list. Indeed, one could argue that most library processes might be looked at in this way, considering whether there are benefits in shared approaches or in externalising some activities.
It is also clear that many of these services are about logistics, using that term broadly to mean the effective management and distribution of materials through a network to meet particular needs. And as I suggested above, the Document Supply Centre was set up as a central part of library logistics in the UK. Logistics or supply chain management becomes very important in a network environment. Just as workflow co-ordinates components for the user, so supply chain management or logistics services co-ordinate the assembly of components to support particular processes. Much of what logistics does is use data to configure a network of participants for efficient working. This data is the 'intelligence' in the network. I have already mentioned some of the data that is useful in this regard:
- Registries of system entities (services, collections, policies, institutions, licences, ...). Pieces of this exist. See for example the Information Environment Service Registry or openurl.ac.uk, or the various aggregations of collection descriptions.
- Aggregation of data about behaviours, preferences, choices (for example circulation records, holdings data, resolver traffic, database usage data, ...). This aggregate data is useful for driving management decisions (which books to digitise for example) or developing services (eg recommender services).
- Registry of statements about information objects. This is a somewhat clumsy formulation, but what I am thinking of are initiatives like the registry of digital masters which records digitisation and preservation intent. We may want to associate copyright statements with objects: think of the requirements of the mass digitisation initiatives.
Having said that libraries will benefit from further shared services, which consolidate effort and build capacity, how should those services be secured? This question can be asked at several levels. For example, one could have collective strategising about futures. One could have collective procurement of consolidated resources. One could operate consolidated resources. To some extent JISC does all of this now, but not across the range of library activity. The Research Information Network is developing a collective strategising role. The British Library was a 'logistics hub' historically; will it develop into some of these newer services?
And there are a variety of commercial and other players who can offer services. In fact, there are now many organisations which are looking at removing redundancy and building capacity in various contexts: think of the California Digital Library within the University of California; think of OhioLink; of OCLC or Bibsys; or the Danish Electronic Research Library (DEF); and so on.
Putting Libraries on the Network
From a network service point of view, much of what I have discussed, in the last section and earlier, leads to the same architectural conclusion: the modularisation of services so that they can be recombined as occasion demands, whether brought together in the library offering or brought together in the user environment, and the ability of data and content to flow between systems and into user environments. This is the case whether the library wants to pull together services and context from various external services, or whether it wants to project particular combinations of services into user environments.
In some cases we are looking at very new ways of doing things, within environments which are increasingly stitched together with the light-weight approaches which have emerged in recent years: RSS, URL-based protocol approaches, and an array of browser-based toolbars, extensions and scripts. In fact, I have emphasised that there is a proliferation of potential 'composition frameworks', environments in which people are organising their personal, learning or work digital lives, and are creating workflows. In no particular order, think of RSS aggregators, services like my.yahoo or netvibes, SAKAI, uPortal, the MicroSoft Reseach pane, or its successors. How does one reach into all of those, particularly as things change so quickly?
Approaches like the JISC/DEST e-Framework may help in enumerating services, but there is a prior question: what are the services that the library should provide, what is going to the be the service portfolio in 2010 or 2015, in what ways will the library create value in the research and learning process? Put another way, what library services do I want to see in my.yahoo, or in my RSS aggregator, or the Microsoft Research Pane, etc ? How does the library expose content and services that can be remixed, that can be integrated into workflows, and that can be repurposed to meet specific needs?
In this article I have been guided by a sense of the library which has the following broad service areas:
- Discovery to delivery (discover, locate, request, deliver) - providing services which unite users with relevant resources.
- Create to Curate (creation, organisation, curation) - providing services which allow users and the library to create, analyse, organise, select, acquire, store, and preserve resources.
- Connect, advise and collaborate - providing services that connect users to expertise, to each other, to library staff, to collaborators.
But within those very broad areas, there is much scope for discussion about emphasis and value.
More specifically, here are some examples of where there is active discussion of how services should be exposed:
- A service layer for repositories. We have various repository frameworks, but no generally agreed consistent machine interfaces for search/harvest/get/put/update.
- A service layer for integrated library system functions. Various services will need to talk to the integrated library system. Think for example of wanting to check availability or place a hold or search the system from within another interface. Currently, people are using brittle scripting and scraping mechanisms, or proprietary URL syntaxes. An agreed set of simple interfaces would be good.
- A registries framework. As I noted, we are building registries in many places. Registries for services, collections, institutions, and so on are increasingly important. Should we have a consistent way of exposing such registries on the network, again for search/harvest/get/put/update?
One could multiply these examples. The same issue arises with already familiar processes, where we want to expose them in new ways, as does occur when we think of more transformative scenarios [33].
More generally, we are seeing some convergence on OpenURL, OAI-PMH and SRU/W and its family of retrieval approaches. However, these increasingly need to interface at various levels with the 'sloppier' general approaches of OpenSearch, RSS, and simple Web services. We may have to expose services as 'portlets' for integration into various portal frameworks.
This all points to the need for greater agility in service development, which further emphasises the need for other areas of work to be carried out in shared venues. The library needs solutions which meet user needs.
Systemic Working: The Project Phenomenon
I began by talking about the programmatic initiatives that were very much alive in the early to mid-nineties. Those centrally funded programmatic activities were very important in supporting a community discussion about what it meant to move into a network environment. They are foundational in that sense. They were followed by major investment in project-based activity in subsequent years.
Project activity is useful for staff development, maybe for plugging particular gaps or achieving some local goals, for getting institutions to work together. The skills developed in particular projects may later be deployed in developing new services or initiatives.
But project-based funding is not the way to go to introduce much of the systemic change that is now again required. Projects tend to be institutional or consortial: it is difficult for these to operate at the level of the system. Of course, their results may be transferable, but this does not always happen. And it does not happen for good reason: a project will develop its own requirements and deliverables, which may not transfer easily into a production environment somewhere else. There is often a large gap between a project output and a 'product' in the sense that something is ready to meet broader objectives. Projects may not produce portable solutions. Widescale project working also has another interesting dynamic. It disperses rather than concentrates expertise, and given that expertise is a finite resource it means that many individual projects may achieve less than fewer larger ones would. There is also an opportunity cost, as expertise is devoted to projects, and it may be difficult to align project goals and institutional needs. Of course, this is to state the extreme case: there may be some institutional benefit.
The absence of systemic attention, the dispersal of expertise, and the lack of a 'product' focus can be seen as issues in several recent programmes. Think of the range of digitisation projects in recent years in the UK [34]. This is not to say that there should not be support for R&D. Or that we should not find ways to reward and sustain creativity and innovation. Clearly we should. But we should realise what a programme of projects can produce. This should not be confused with designing, building and sustaining the library services that will effectively support research and learning into the future.
Conclusion
At the end of the Ariadne decade, we are still looking at change. I have suggested that there is a neat coincidence in that each end of the decade falls at a significant moment. The first saw the convergence of the Web and broad-based connectivity to create a new social space for research and learning. The second, whether one wants to use the Web 2.0 label or not, involves the convergence of the programmable Web and connectivity which is broadband and wireless. It is the age of Amazoogle. I have discussed some of the system changes in the flat network world, how research and learning behaviours are changing as they become meshed with the network, and what some of these things mean for library services. In summary, I have emphasised three broad issues:
- Much of our work, learning and research activity is being reshaped in a network environment. This will have a profound effect on library services. In fact, the effect of technology on research and learning behaviours will have a greater impact than the direct effect of technology on library systems and services themselves. In the medium term, the library will need to engage with major shifts in research and learning practice. In the short term, the library needs to begin building services around user workflows, supporting the remix of content and services in user environments, and developing digital curation services.
- The network has created a new dynamic of discovery and use around major hubs of information infrastructure: Google, Amazon, iTunes and so on. They have aggregated supply (unified discovery and reduced transaction costs), aggregated demand (brought a large audience to bear), and are developing into platforms which help other applications reach their goals. These will not replace library services, but they have caused us to think about how to deliver service on the Web. Although the collective library resource is deep, fragmentation of discovery and high transaction costs have reduced impact. Libraries are exploring how better to project a targeted service into user environments, how to develop a switch between the open Web and rich library services, and how to make services more engaging.
- It is not possible for every library to support and manage all of its 'business processes', especially as the demand on the library grows, and service expectations and technologies change so quickly. Libraries have historically depended on shared platforms for services, and we may be about to see another step change in adoption. The motivation is to remove redundancy and to build capacity through collaboratively sourcing solutions, so as better to focus library effort on where it can make a distinctive local impact on the quality of the research and learning environment.
The notion of the 'well-found' library was current in the UK some years ago. What does it mean to be well-equipped for the job? What is the nature of a library service that appropriately supports research and learning needs in our current environment, or a few years hence? Jerry Cambpell, writing in Educause Review, recently asked this question in different terms.
Although these emerging, digital-age library services may be important, even critical, in the present era, there is no consensus on their significance to the future academic library-or even on whether they should remain as library functions carried out by librarians. In addition, at this point, the discussion of the future of the academic library has been limited to librarians and has not widened, as it should, to involve the larger academic community. Consequently, neither academic librarians nor others in the academy have a crisp notion of where exactly academic libraries fit in the emerging twenty-first-century information panoply. 35
This is an ongoing question as research, learning and information use are reconfigured.
The UK is well placed to collectively strategise about the future contours of the academic library, and about what collective steps should now be taken so that the library remains a vital partner in the academic enterprise.
References
- For a discussion of eLib see: Chris Rusbridge. "Towards the hybrid library". D-lib Magazine, July/August 1998. http://www.dlib.org/dlib/july98/rusbridge/07rusbridge.html
- For a discussion of the European Libraries Programme and UK participation see: Lorcan Dempsey. "The UK, networking and the European Libraries Programme." Library and Information Briefings, Issue 57, February 1995.
- For a discussion of the NSF Digital Library Initiative from this period, see the special issue of D-Lib Magazine, July/August 1996 at http://www.dlib.org/dlib/july96/07contents.html
- For discussion of the hybrid library see Chris Rusbridge, op cit. and Stephen Pinfield and Lorcan Dempsey. "The Distributed National Electronic Resource (DNER) and the hybrid library". Ariadne, January 2001, Issue 26. http://www.ariadne.ac.uk/issue26/dner/
- For an overview of OSI, the library OSI protocol framework, and library network activity from the early nineties see Lorcan Dempsey. Libraries, networks and OSI. 2nd Edition. Westport, CT and London: Meckler, 1992.
- Stuart Weibel. Metadata: the foundation of resource description. D-Lib Magazine, July 2005. http://www.dlib.org/dlib/July95/07weibel.html (I include this reference as it is from the first issue of D-Lib Magazine!)
- Derek Law. "The development of a national policy for dataset provision in the UK: a historical perspective". Journal of Information Networking, 1(2), 1994, p.103-116.
- Derek Law and Lorcan Dempsey. "A policy context - eLib and the emergence of the subject gateways". Ariadne, September 2000, Issue 25. http://www.ariadne.ac.uk/issue25/subject-gateways/
- salesforce.com http://www.salesforce.com/
- WebEx http://www.webex.com/
- Of course, the discussion of distributed applications is familiar from a decade ago and more: what is different here is that we are seeing more being built from lighter-weight technologies.
- Thomas Davenport. The coming commoditization of processes. Harvard Business Review, June 2005. pp 101-108.
- Thomas L Friedman. The world is flat: a brief history of the twenty-first century. New York : Farrar, Straus and Giroux, 2005. http://www.worldcatlibraries.org/wcpa/isbn/0374292884
- This discussion is based on: Lorcan Dempsey. "The user interface that isn't". May 2005. http://orweblog.oclc.org/archives/000667.html
- Chris Anderson. "The long tail". Wired Magazine, Issue 12.10 - October 2004. http://www.wired.com/wired/archive/12.10/tail.html
- Examples here are the use of Flickr by the National Library of Australia (http://australianit.news.com.au/articles/0,7204,17983872%5E15317%5E%5Enbv%5E15306,00.html) and the use of iTunes by Stanford (http://itunes.stanford.edu/)
- Palmer, Carole L. (2005). Scholarly Work and the Shaping of Digital Access. Journal of the American Society for Information Science 56, no. 11: 1140-1153.
- Raymond Yee. GatherCreateShare. http://raymondyee.net/wiki/GatherCreateShare
- This section is based on: Lorcan Dempsey. "In the flow". June 24, 2005. In the flow (lorcandempsey.net)
- Nancy Fried Foster and Susan Gibbons. "Understanding Faculty to Improve Content Recruitment for Institutional Repositories". D-lib Magazine, January 2005. http://www.dlib.org/dlib/january05/foster/01foster.html
- IRRA. Institutional repositories and research assessment. http://irra.eprints.org/
- For an overview of institutional repositories see the following articles. Gerard van Westrienen and Clifford A. Lynch. "Academic Institutional Repositories: Deployment Status in 13 Nations as of Mid 2005". D-Lib Magazine, September 2005. http://www.dlib.org/dlib/september05/westrienen/09westrienen.html
Clifford Lynch and Joan Lippincott. "Institutional Repository Deployment in the United States as of Early 2005". D-Lib Magazine, September 2005. http://www.dlib.org/dlib/september05/lynch/09lynch.html - Figure 1: "A Learning Landscape" comes courtesy of David Tosh and Ben Werdmuller of the Elgg Development Team, see http://elgg.org/ . Their presentation was entitled: Creation of a learning landscape: weblogging and social networking in the context of e-portfolios. Powerpoint at http://elgg.net/dtosh/files/260/568/creation_of_a_learning_landscape.ppt
- Figure 2 is adapted from the OCLC Environmental Scan (see http://www.oclc.org/reports/escan/research/newflows.htm), which is in turn adapted from Liz Lyon, Lyon, Liz . "eBank UK: Building the links between research data, scholarly communication and learning," Ariadne, July 2003, Issue 36. http://www.ariadne.ac.uk/issue36/lyon/
- Lorcan Dempsey. The integrated library system that isn't. The integrated library system that isn't (lorcandempsey.net)
- Roland Dietz & Carl Grant. "The Dis-Integrating World of Library Automation" Library Journal, June 15, 2005. http://www.libraryjournal.com/article/CA606392.html
- Carole Palmer. Thematic research collections. In: A companion to digital humanities. Susan Schreibman , Raymond George Siemens , John Unsworth (eds). Malden, MA : Blackwell Pub., ©2004. http://www.worldcatlibraries.org/wcpa/isbn/1405103213 (Preprint at http://people.lis.uiuc.edu/~clpalmer/bwell-eprint.pdf)
- John Unsworth. The Crisis in Scholarly Publishing: Remarks at the 2003 Annual Meeting of the American Council of Learned Societies. http://www.iath.virginia.edu/~jmu2m/mirrored/acls.5-2003.html
- The Rossetti Archive http://www.rossettiarchive.org/
- Edward L Ayers. "The valley of the shadow: two communities in the American Civil War". http://valley.vcdh.virginia.edu/
- Further details about Open WorldCat at http://www.oclc.org/worldcat/open/default.htm
- Chems Consulting. Optimising Storage and Access in UK Research Libraries. A report for CURL and the British Library. September 2005. http://www.curl.ac.uk/about/documents/CURL_BLStorageReportFinal-endSept2005.pdf
- Herbert Van de Sompel et al. Rethinking Scholarly Communication: Building the System that Scholars Deserve. D-Lib Magazine, Volume 10 Number 9, September 2004. http://www.dlib.org/dlib/september04/vandesompel/09vandesompel.html
- Barbara Bultman et al. Digitized content in the UK research library and archives sector. http://www.jisc.ac.uk/uploaded_documents/JISC-Digi-in-UK-FULL-v1-final.pdf
- Jerry D. Campbell. Changing a Cultural Icon: The Academic Library as a Virtual Destination. EDUCAUSE Review, vol. 41, no. 1 (January/February 2006): 16-31. http://www.educause.edu/apps/er/erm06/erm0610.asp
Author Details
Lorcan Dempsey
VP Research & Chief Strategist
OCLC
Email: dempseyl@oclc.org
Web site: http://orweblog.oclc.org
Article Title: "The (Digital) Library Environment: Ten Years After"
Author: Lorcan Dempsey
Publication Date: 08-February-2006
Publication: Ariadne Issue 46
Originating URL: http://www.ariadne.ac.uk/issue46/dempsey/
Facebook Twitter Google+ E-Mail Pinterest LinkedIn
Ariadne is published by Loughborough University Library
© Ariadne ISSN: 1361-3200. See our explanations of Access Terms and Copyright and Privacy Statement.
Picture: The opening picture is taken at the University of Warwick (UnSplash). Many of the planning meetings for UK national library initiatives were held in the University of Warwick Conference Centre. The picture is not part of the original article.
Provenance: I originally published this article on 8 February, 2008, in the Ariadne magazine. I copy it here as I reference it while discussing my writing, and I wanted the reference to work correctly. I do regret the use of 'flat world' which was a popular expression at the time (originating with Tom Friedman of the NYT). It was not great then :-) and has not weathered well. This might be the moment to confess that I have an article somewhere with 'information superhighway' in the title.
 Lorcan’s posts
Lorcan’s posts