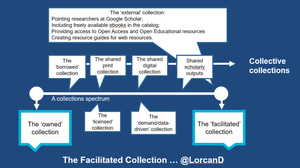
Over the coming years we will take a more active role in managing aggregate or collective collections: thinking about the best disposition of collections within particular inter-institutional policy environments. The opportunity costs of managing print collections will ensure that this happens. My colleague and I state this as follows in an article just published in D-Lib Magazine:
The print book is core to library identity and practice, but in an era of zero-sum budgets, it is almost inevitable that print book budgets will decline as budgets for serials, digital resources, and other materials expand. As libraries re-allocate resources to accommodate changing patterns of user needs, print book budgets may be adversely impacted. Of course, the degree of impact will depend on a library’s perceived mission. A public library may expect books to justify their shelf-space, with de-accession the consequence of minimal use. A national library, on the other hand, has a responsibility to the scholarly and cultural record and may seek to collect comprehensively within particular areas, with the attendant obligation to secure the long-term retention of its print book collections. The combination of limited budgets, changing user needs, and differences in library collection strategies underscores the need to think about a collective, or system-wide, print book collection – in particular, how can an inter-institutional system be organized to achieve goals that would be difficult, and/or prohibitively expensive, for any one library to undertake individually [4]?[Anatomy of Aggregate Collections: The Example of Google Print for Libraries]
The multiplication of off-site storage facilities, the pressure on space, and the growing interest in coordinated collection development and digitization have made these questions very timely.
In turn it is very difficult to plan sensibly without data to support sensible decisions: data about collections and use. What this paper does is take the collections of the ‘Google 5’ libraries – the libraries partnering with Google in the digitization of their collections – and looks at characteristics of their collections when treated as a single unit. The results are interesting and sometimes counterintuitive. The analysis takes place within the context of WorldCat, the largest available record of book collections we have. The study looked at ‘books’ only, of which there are 32M represented in WorldCat (see the paper for how book is defined).
Some interesting results:
- The proportion of the system-wide collection actually covered by the G5 libraries, once duplicate holdings across the five institutions are removed, is about one third (33 percent), or 10.5 million unique books out of the 32 million in the system-wide collection.
- The pattern of cross-collection overlap implies that if each collection were fully digitized, about four out of every ten books would be re-digitized at least once, or in other words, the Googge Print Libraries project reflects a minimum redundancy rate of about 40 percent.
- The pattern of cross-collection overlap suggests that research library collections may be less ‘vanilla’ than might have been thought, or in other words, as the article states, ‘rareness is common’. Only 3% of the books in the 10.5M are held by all five libraries.
- More than 430 languages were identified in the Google 5 combined collection. English-language materials represent slightly less than half of the books in this collection; German-, French-, and Spanish-language materials account for about a quarter of the remaining books, with the rest scattered over a wide variety of languages. At first sight this seems a strange result: the distribution between English and non-English books would be more weighted to the former in any one of the library collections. However, as the collections are brought together there is greater redundancy among the English books.
- Approximately half of the print books in the combined Google 5 collection were published after 1974. Almost three-quarters were published after the Second World War. Using the year 1923 as a rough break-off point between materials that are out of copyright and materials that are in copyright [16], more than 80 percent of the materials in the Google 5 collections are still in copyright (this is of course an upper bound).
The paper contains other data also and we plan to continue the work in various ways. As we move forward, we need to understand more about the characteristics of our collections so as to make better decisions about them. This is an area where union catalogs will again come into their own.
Note: this is the type of discussion where one wants to continually qualify what one means by book. In FRBR terms, manifestation is usually what is meant here.
Related entries: