Today Google and CIC announce an agreement to digitize ten million volumes across the CIC libraries. Google has been adding new partners since the first announcement was made about the Google 5. Some folks have wondered what rationale has governed selection of partner opportunities. We do not know, but they sure are moving fast! Here are some early thoughts.
The CIC announcement is interesting for several reasons:
- It is a shared effort across a major group of libraries with significant collections. There appears to be strong CIC institutional commitment. Of course, CIC has a history of collaboratively sourced activities and this ‘pooling’ model makes increasing sense given the necessary policy and service challenges that need to be addressed. In this case, but also across a range of other issues that libraries face as they support changing research and learning behaviors in a reconfigured network environment. For some things, scale matters.
- The libraries have a shared approach to managing the digital copies based on shared infrastructure at the University of Michigan, and serving them up to their user communities. An example of collaborative sourcing.
- Google recently advertized for somebody to work on collection development and we seem to be seeing a stronger focus in this area. Collecting areas of importance within each library [pdf] have been identified for attention. Presumably, these decisions have been influenced by the ‘collective collection’ of the full Google partnership also.
This initiative in turn prompts some more general thoughts about access:
- One of the most valuable features of the Google initiative is that it digitizes book content, allowing fine-grained discovery over topics, people, places and so on. Of course this presents interesting questions about indexing, retrieval, ranking, and presentation but the advantage of having this access seems clear. It drives use and sales, and it supports enquiry. Without it, the book literature is less accessible than the web literature.
- However, as we are beginning to see on Google Book Search, we are really going beyond ‘retrieval as we have known it’ in significant ways. Google is mining its assembled resources – in Scholar, in web pages, in books – to create relationships between items and to identify people and places. So we are seeing related editions pulled together, items associated with reviews, items associated with items to which they refer, and so on. As the mass of material grows and as approaches are refined this service will get better. And it will get better in ways that are very difficult for other parties to emulate.
- Currently this material is made available within the Google destination site. Google is an advertizing engine and its approach depends on aggregating attention for adverts. This apporach may be difficult to deploy within a more ‘data services’ approach where others – especially the partners – have remixable access to content and services. However, the ‘utility’ value of this resource will be diminished if it is not made available in this way so that others can mobilize these resource within their own environments. How and if this gets done remains to be seen. (See the related discussion about the search API.)
- This type of access seems especially important for the partner libraries. In the early days of this activity there was some discussion of the types of services which would be built on top of the digitized books by the libraries. However, it is difficult, and maybe not very sensible, for the libraries to individually invest in some types of service development. An important factor here is that they cannot benefit from the network effects that arise in larger collections and so are limited in the range of service that they could individually develop. This points again to issues of collaborative sourcing.
For me, the CIC announcement moves the conversation about mass digitization to another level. The Google relationship with libraries has seemed like an interesting initiative. But it now seems plausible to think that we are looking at systemic change in how we engage with particular classes of material. Which in turn will cause us to look at the way in which the systemwide library resource is organized. It touches on so much:
- Disclosure, discovery, delivery. This initiative highlights the changing dynamic of discovery and delivery in a network environment. As folks have richer discovery experiences on the network, it becomes more important for libraries to disclose what they have into those environments and to offer well-integrated fulfilment services. A library will want a user of Google Book Search to know what is available to him or her within their own institution. Of course, Google currently links through to library services but this needs to get smoother.
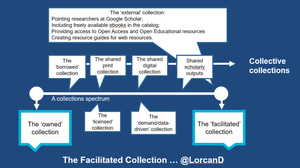
- Collective collection. As more materials are digitized it promotes stronger thinking about collective approaches to collection management: from access, development, inventory management and preservation perspectives. This direction is visible in emerging discussions about offsite storage and uses of library space. Over the next few years, I believe we will see major initiatives which address these issues in collective ways.
- Copyright. Issues here are well-known and debated. For libraries – and others – it is important to be able to efficiently determine the copyright status of an item, at various stages in the life-cycle. We cannot now do this, not efficiently, and certainly not in any way that can be automated and made available as a ‘data service’ for easy checking by applications. There are several initiatives looking at this, among them OCLC, who is exploring the feasibility of a Registry of Copyright Evidence.
- Knowledge organization. Libraries, archives, museums and others have made major investments in structured data in the form of taxonomies, gazeteers, authority lists, and so on. The value of those resources needs to be released in web environments. As Google refines its approaches to text mining, or if others are able to do computational work over the resource, then there is an interesting opportunity to see how they might be mobilized to support identity identification (of personal names, place names, and so on) in large amounts of text, and how those tools might themselves be enhanced in the process.
- Preservation. Libraries and related organizations have collectively exercised a responsibility to the scholarly and cultural record. They have safeguarded rare materials. They have also managed the broad range of published output. And much of this has been as a benign consequence of the physical print distribution model. Lots of copies keeps stuff safe. Of course, the digital environment changes this dynamic also. So, we need to think about keeping the digital copies that emerge from this process. But it also highlights issues around the management of the collective print resource moving forward and how that responsibility is dispersed. And it raises interesting questions about what we expect from a digital version of the print record in terms of quality, coverage, specificity and so on which will keep us busy for some time.
Much of what I have said revolves around systemic issues: how does the systemwide library resource reconfigure in a network environment which is seeing this type of change. This requires collective responses, which is why I think that this CIC initiative is so interesting. For OCLC, and the other library organizations which operate at the systemic level, it underlines the importance of working with libraries to develop web-scale, or in other words, responses which match what users now expect in a web environment.
Picture: Feature picture taken by the author. Added 7 November 2022. The CIC is now the Big 10 Academic Alliance (BTAA).