Thinking about book content indexing again ….
John Battelle announced the Alexa Web Search Platform on his blog earlier today.
In short, Alexa, an Amazon-owned search company started by Bruce Gilliat and Brewster Kahle (and the spider that fuels the Internet Archive), is going to offer its index up to anyone who wants it. Alexa has about 5 billion documents in its index – about 100 terabytes of data. It’s best known for its toolbar-based traffic and site stats, which are much debated and, regardless, much used across the web. [John Battelle’s Searchblog: Alexa (Make that Amazon) Looks to Change the Game]
This has resulted in a great deal of blog buzz wondering if search is becoming a commodity and what it means. It is also interesting as it moves Amazon’s web services activity into a new area, making web search functionality available for stitching into other applications.
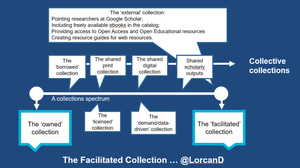
Now, one potential advantage of the book mass digitisation initiatives currently underway is that they are potentially creating a ‘book content index’ in the way that the search engines currently have a ‘web content index’. Amazon is opening up a business which makes that ‘web content index’ available to other applications through its APIs. Which leads to an interesting question: Will Amazon open up its ‘search inside the book’ indexes in this way also (or can it)? Or will another player – Google for example – develop such a service? Or … Does anybody yet have a critical mass, or will they soon?
Such a service would be very useful, and if offered in an appropriate way could be integrated into library catalogs or other library services. Indeed, libraries could build vertical applications on top of such a service.
It seems that within a few years we will have a book content index. One of the questions for the library community will be how to use it. Another will be how to make sure that parts of the scholarly or cultural record that are not attractive to current mass digitization initiatives are not rendered less accessible over time because they are not being indexed in this way.
Related entries: